Tags: sekaictf2022 vocaloid_heardle
Rating:
# SEKAI CTF 2022: Vocaloid Heardle
- [Problem Description](#problem-description)
- [Files Provided](#files-provided)
- [Step 1: How the flag is generated](#step-1-how-the-flag-is-generated)
- [Step 2: Reversing the code](#step-2-reversing-the-code)
- [Step 2.1: Understand how FFMPEG works](#21-understand-how-ffmpeg-works)
- [Step 2.2: When life gives you ffmpeg, make a bunch of audio files](#22-when-life-gives-you-ffmpeg-make-a-bunch-of-audio-files)
- [Step 2.3: The end justifies the means](#23-the-end-justifies-the-means)
- [Step 3: Stumbling upon gold](#step-3-stumbling-upon-gold)
- [Step 4: Getting the flag](#step-4-getting-the-flag)
## Problem Description
> Well, it’s just too usual to hide a flag in stegano, database, cipher, or server. What if we decide to sing it out instead?
>
> Author: pamLELcu
>
> See challenge here: https://ctf.sekai.team/challenges#Vocaloid-Heardle-23
## Files Provided
1. `vocaloid_heardle.py`
2. `flag.mp3`
## Step 1: How the flag is generated
After looking at the files, it became clear that `vocaloid_heardly.py` is the file used to generate `flag.mp3`:
Let's imagine that the flag is `SEKAI{THIS_IS_MY_FIRST_WRITEUP}`. Given this flag, the python script:
1. Removes the enclosing `SEKAI{...}` to get the inner substring `THIS_IS_MY_FIRST_WRITEUP`.
2. Converts each character to unicode:
ord(' T ') = 84
ord(' H ') = 72
ord(' I ') = 73
...
3. Gets all musics with musicId equal to the characters' unicodes and downloads it, storing them into the array `tracks`:
```python
# returns a random assetbundleName from the list of all musics with musicId equals to the given input mid
def get_resource(mid):
return random.choice([i for i in resources if i["musicId"] == mid])["assetbundleName"]
def download(mid):
resource = get_resource(mid)
r = requests.get(f"https://storage.sekai.best/sekai-assets/music/short/{resource}_rip/{resource}_short.mp3")
filename = f"tracks/{mid}.mp3"
with open(filename, "wb") as f:
f.write(r.content)
return mid
tracks = [download(ord(i)) for i in flag]
# here is how tracks look like after execution:
# tracks = [
# 'vs_0084_01', --> musicId = 84 ('T')
# '0072_01', --> musicId = 72 ('H')
# 'se_0073_01' --> musicId = 73 ('I')
# ...
# ]
```
4. Stitches together the given music files using `ffmpeg` to generate `flag.mp3`:
```python
# stage 1
inputs = sum([["-i", f"tracks/{i}.mp3"] for i in tracks], [])
# stage 2
filters = "".join(f"[{i}:a]atrim=end=3,asetpts=PTS-STARTPTS[a{i}];" for i in range(len(tracks))) + \
"".join(f"[a{i}]" for i in range(len(tracks))) + \
f"concat=n={len(tracks)}:v=0:a=1[a]"
# stage 3
subprocess.run(["ffmpeg"] + inputs + ["-filter_complex", filters, "-map", "[a]", "flag.mp3"])
# stage 1:
# inputs = [
# '-i', 'tracks/vs_0084_01.mp3',
# '-i', 'tracks/0071_01.mp3',
# '-i', 'tracks/se_0073_01.mp3',
# ...
# ]
# stage 2:
# filters = '[0:a]atrim=end=3,asetpts=PTS-STARTPTS[a0];[1:a]atrim=end=3,asetpts=PTS-STARTPTS[a1];[2:a]atrim=end=3,asetpts=PTS-STARTPTS[a2]; ...'
# stage 3:
# ffmpeg -i tracks/vs_0084_01.mp3 -i ... -filter_complex <filters> -map [a] flag.mp3
```
## Step 2: Reversing the code
Having understood how the flag is generated, the obvious next step is to somehow figure out (1) which music files make up `flag.mp3`, (2) get the corresponding musicIds from the file names, and (3) convert the musicIds from unicode to ASCII.
### 2.1 Understand how FFMPEG works
I needed to Google a bit to figure out what the `ffmpeg` instruction was doing specifically.
I stumbled upon a [stackoverflow post](https://superuser.com/a/1121879) that teaches us to concatenate two audio files via `ffmpeg`'s `filter_complex`.
Here is a visualization of how `ffmpeg` commands work for the above example:

`ffmpeg` accepts some input files via the `-i` option, then performs a series of filters via the `-filter_complex` option (which are separated by semicolons), and finally outputs & saves the final output stream `[a]` as `flag.mp3`.
You can learn more about how `ffmpeg` works [here](https://www.opensourceforu.com/2015/04/get-friendly-with-ffmpeg).
Diving deeper into `filter_complex`, I learned what the [atrim](https://ffmpeg.org/ffmpeg-filters.html#atrim) and [asetpts](https://ffmpeg.org/ffmpeg-filters.html#setpts_002c-asetpts) filters do in stage 2:
> "atrim=end=3" will stop trimming at 3 seconds
> "asetpts=PTS-STARTPTS" will specify to start at the first frame
Thus, stage 2 is essentially trimming the first 3 seconds of all the audio files and concatenating them together in the order of input:
```python
# stage 2
filters = "".join(f"[{i}:a]atrim=end=3,asetpts=PTS-STARTPTS[a{i}];" for i in range(len(tracks))) + \
"".join(f"[a{i}]" for i in range(len(tracks))) + \
f"concat=n={len(tracks)}:v=0:a=1[a]"
```
A quick sanity check confirms that our hypothesis is true: `flag.mp3` is an audio file that lasts for 33 seconds (multiple of 3), and while playing the audio file we learn that every 3 seconds the music changes.
Thus, the inner substring of the flag must contain 33 / 3 = 11 characters!
### 2.2 When life gives you ffmpeg, make a bunch of audio files
Why not immediately make use of all the knowledge we've learned about `ffmpeg`?
A quick google search taught me [how to split an audio file into equal segments](https://unix.stackexchange.com/questions/280767/how-do-i-split-an-audio-file-into-multiple) using `ffmpeg`:
```
ffmpeg -i flag.mp3 -f segment -segment_time 3 -c copy flag_char_%03d.mp3
```
This generated precisely 11 files:
```
? vocaloid_heardle
┣ ? flag.mp3
┣ ? vocaloid_heardle.py
┗ ? flag_chars
┣ ? flag_char_000.mp3
┣ ? flag_char_001.mp3
┣ ? flag_char_002.mp3
┣ ? flag_char_003.mp3
┣ ? flag_char_004.mp3
┣ ? flag_char_005.mp3
┣ ? flag_char_006.mp3
┣ ? flag_char_007.mp3
┣ ? flag_char_008.mp3
┣ ? flag_char_009.mp3
┗ ? flag_char_010.mp3
```
### 2.3 The end justifies the means
One hour into the challenge and I was determined to solve this CTF. My teammates probably got tired of hearing me repeatedly play `flag.mp3`. It is about time for me to tell them "I found the flag!!"
Okay, we got the individual audio files. Now we need to know which musicId each of the `flag_char_XXX.mp3` corresponds to.
~~What's the most algorithmically efficient way to do that?~~
Brute force. Brute force is the way.
And so that's what I did:
- I scraped and downloaded all 638 music files (>500MB) provided by `resources.json`:
```python
# get all possible resourceID from resources.josn
def scrape():
with open("resources.json", "r") as f:
resources = json.load(f)
# download all possible assetBundleNames
for resource in resources:
ass = resource["assetbundleName"]
print("getting asset:", ass)
r = requests.get(f"https://storage.sekai.best/sekai-assets/music/short/{ass}_rip/{ass}_short.mp3")
# write to a new file
filename = f"tracks/{ass}.mp3"
with open(filename, "wb") as f:
f.write(r.content)
print(f"wrote to file: tracks/{ass}.mp3")
# sit and wait
scrape()
```
Now my folder looks like this:
```
? vocaloid_heardle
┣ ? flag.mp3
┣ ? vocaloid_heardle.py
┣ ? flag_chars
┃ ┣ ? flag_char_000.mp3
┃ ┣ ? flag_char_001.mp3
┃ ┗ ...
┗ ? tracks # 638 MP3s (>500MB)
┣ ? 0001_01.mp3
┣ ? 0002_01.mp3
┗ ...
```
Here comes the hard part: figuring out which audio file maps to each of the `flag_char_XXX.mp3`.
- Attempt 1: I tried using python difflib's [SequenceMatcher](https://docs.python.org/3/library/difflib.html), but was not able to find matching audio files. My guess is that while performing `ffmpeg` the sequence of bytes may not necessarily align perfectly.
```python
# DID NOT WORK
from difflib import SequenceMatcher
def compare():
# loop through all track files
with open("resources.json", "r") as f:
resources = json.load(f)
for resource in resources:
ass = resource["assetbundleName"]
# use ffmpeg to compare file with all 12 flags
def similar(a, b):
return SequenceMatcher(None, a, b).ratio()
def brute_force_flag_char(file_name):
file_to_brute = open(file_name, "rb").read()
# loop through all track files
with open("resources.json", "r") as f:
resources = json.load(f)
for resource in resources:
ass = resource["assetbundleName"]
# use ffmpeg to compare file with all 12 flags
file2 = open(f"trim_tracks_mp3/{ass}_3s.wav", "rb").read()
sim_ratio = similar(file_to_brute, file2)
if sim_ratio > 0:
print(f"{sim_ratio}: {ass}")
# sit and wait
for i in range(11):
brute_force_flag_char(f"flags/flag_char_{i:03}.mp3")
```
- Attempt 2: I then tried using [audiodiff](https://github.com/SteveClement/audiodiff), but again it didn't work.
At this point I felt defeated.
Maybe I implemented someting wrongly...
### Step 3: Stumbling upon gold
Then, after some more Googling, I stumbled upon gold: [Sononym](https://www.sononym.net/)
It is a free software that allows you to find similar sounding samples in a sample collection with simple drag-and-drop UI:
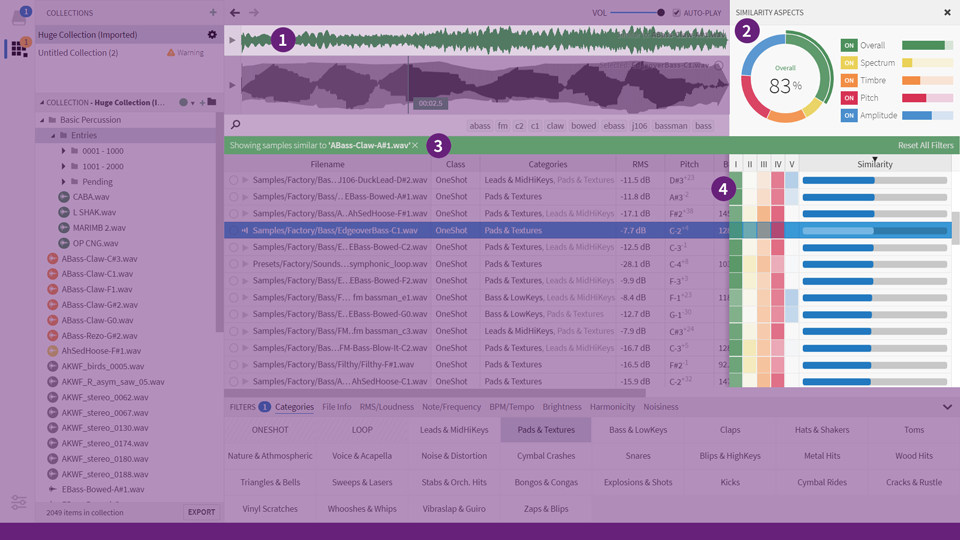
I downloaded the software. Dragged my `tracks` folder containing 638 audio files into the app. Then dragged `flag_char_000.mp3` in as well.
Lo and behold, an instant 99% match on `vs_0118_01.mp3` which corresponds to `musicId: 118` or `chr(118)` which is the letter `v`!
### Step 4: Getting the flag
Now quickly repeat this for all 11 characters:
| flag characters | musicId files | unicode | ascii |
| ----------------- | --------------- | ------- | ----- |
| flag_char_000.mp3 | vs_0118_01.mp3 | 118 | v |
| flag_char_001.mp3 | 0048_01.mp3 | 48 | 0 |
| flag_char_002.mp3 | 0067_01.mp3 | 67 | C |
| flag_char_003.mp3 | vs_0097_01.mp3 | 97 | a |
| flag_char_004.mp3 | vs_0108_01.mp3 | 108 | l |
| flag_char_005.mp3 | vs_0111_01.mp3 | 111 | o |
| flag_char_006.mp3 | 0073_01.mp3 | 73 | I |
| flag_char_007.mp3 | vs_0100_01.mp3 | 100 | d |
| flag_char_008.mp3 | 0060_01.mp3 | 60 | < |
| flag_char_009.mp3 | vs_0051_01.mp3 | 51 | 3 |
| flag_char_010.mp3 | vs_0117_01 .mp3 | 117 | u |
And at last, the flag has been found:
SEKAI{v0CaloId<3u}
The end must justify the means.
-- Written By [Zi Nean Teoh](https://github.com/zineanteoh)




{kind=link}
{kind=link}